40+ Qwen AI Statistics: How Many People Use Qwen AI? 🤔
Share
Share

Get a quick blog summary with




Qwen AI now powers enterprise software, developer tools, and consumer applications across global markets.
Teams use it for language processing, multimodal generation, coding, and business automation in live production systems.
This statistical roundup is updated for 2026 and presents the latest Qwen AI usage statistics, performance, and adoption statistics. We curated these figures from trusted online sources, including official repositories, research papers, and benchmark reports.
Note: All source URLs are listed at the end of the article for transparency and verification.
Here are Qwen AI statistics at a glance:
- Qwen has accumulated more than 700M total model downloads on Hugging Face as of January 2026, reflecting sustained large-scale global usage across the open source ecosystem.
- During December 2025, Qwen downloads exceeded the combined total of the next 8 largest competing model families, including Meta Llama, DeepSeek, OpenAI, and Mistral, based on AIbase platform tracking.
- Qwen holds the #1 global ranking among all open source model families by total cumulative downloads according to Hugging Face data.
- The Qwen model lineup currently includes more than 20 distinct models, ranging from lightweight 0.6B parameter systems to ultra-large enterprise-scale architectures.
- Qwen reached more than 30 million total monthly active users across mobile, web, and PC platforms within 23 days of its public beta release.
- The Qwen mobile application alone reached 18.34M monthly active users within 2 weeks of its beta launch, based on Aicpb and Yahoo platform data.
- Qwen recorded a 149% month-over-month growth rate in November 2025, making it the fastest-growing AI application globally during that period.
- Qwen surpassed 10M total downloads within 7 days of its November 2025 product relaunch, according to Bloomberg and Artificial Intelligence News reporting.
- Qwen’s official website recorded 25,245 visits with 1,114.64% month-over-month traffic growth in February 2025, reflecting rapid expansion in user interest and platform engagement.
- More than 90,000 enterprises have deployed Qwen models through Alibaba Cloud Model Studio for internal business, analytics, and automation use cases.
Qwen Adoption and Deployment Scale
Qwen AI has been adopted across consumer platforms, enterprise environments, and developer ecosystems as organizations integrate large language models into production workflows. The model family is distributed through open source repositories, cloud APIs, and embedded enterprise software, which has accelerated its global footprint. Usage growth has been driven by both individual developers and corporate deployments operating at scale.
- Qwen achieved a 149% month-over-month growth rate during November 2025, reflecting unprecedented adoption velocity across the AI application market.

- More than 90,000 enterprises have deployed Qwen models through Alibaba Cloud Model Studio for internal and customer-facing use cases.
- Qwen has surpassed 700M cumulative downloads across open source repositories, making it the most widely downloaded model family globally.
- The Qwen ecosystem includes more than 20 individual model variants designed for different performance and cost profiles.
- Qwen’s mobile, web, and desktop applications reached over 30M monthly active users within 23 days of beta launch.
Qwen Model Architecture and Training Scale
Qwen models are built on large-scale training pipelines designed to support multilingual language understanding, code generation, and multimodal reasoning. The architecture spans both dense and Mixture of Experts systems, allowing different models to balance compute efficiency and output quality. Training data is drawn from a wide range of domains and languages to ensure broad coverage and generalization. These design choices allow Qwen models to operate across consumer, enterprise, and research use cases with consistent behavior.
- Qwen3 models were pre-trained on 36 trillion tokens covering multilingual and domain-specific corpora.
- The Qwen3 family supports 119 languages and dialects, expanding multilingual coverage far beyond earlier versions.
- The flagship Qwen3 MoE model contains 235 billion total parameters with 22 billion activated per token.
- Qwen3 dense models range from 0.6 billion to 32 billion parameters across six released sizes.
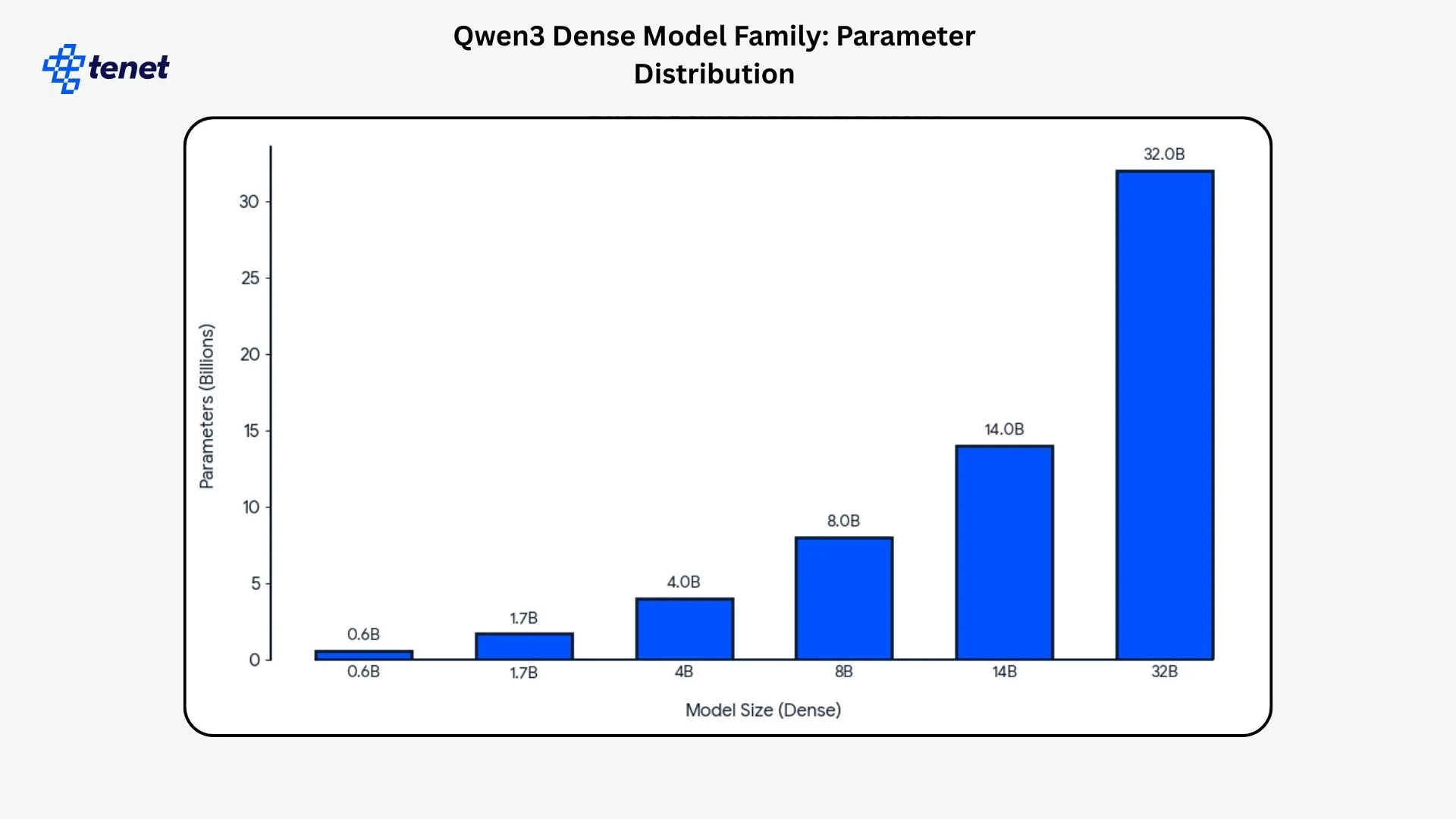
- Qwen3 uses a tokenizer with a vocabulary size of 151,669 tokens for multilingual and technical text handling.
Qwen Performance Across Benchmarks and Real World Tasks
Qwen models are evaluated across standardized academic benchmarks, enterprise coding tests, and applied professional examinations. These evaluations measure reasoning ability, code generation, mathematical problem solving, and domain-specific decision making. Results from independent benchmarking platforms and peer-reviewed studies show that Qwen systems perform competitively against both open source and proprietary models. Performance consistency across tasks is one of the defining characteristics of the Qwen model family.
- Qwen2.5 achieved an overall accuracy of 88.9% on the Chinese National Nursing Licensing Examination across 1,200 multiple-choice questions.
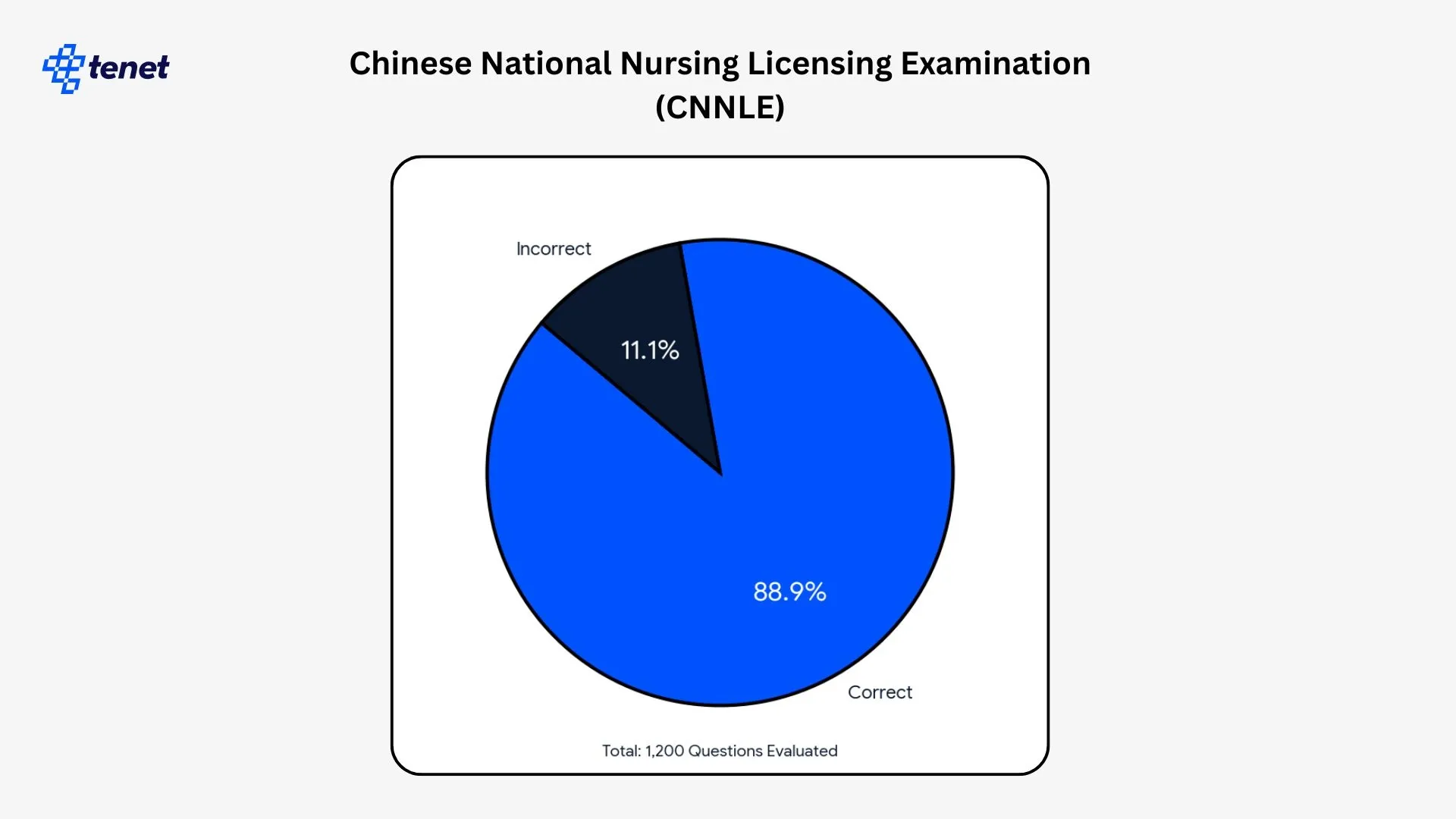
- The ensemble system using Qwen and other models reached 90.8% accuracy when optimized with XGBoost in the same medical examination study.
- Qwen3-235B-A22B scored 85.7 on the AIME 2024 mathematics benchmark.
- Qwen3-235B-A22B achieved 81.5 on the AIME 2025 mathematics benchmark.
- Qwen3-235B-A22B reached a score of 2,056 on the CodeForces competitive programming benchmark.
Qwen User Base and Geographic Distribution
Qwen’s user activity is spread across multiple regions and platforms, reflecting its deployment through web, mobile, and enterprise channels. Traffic data shows that usage is not concentrated in a single country but distributed across emerging and developed markets. Device split metrics indicate how users primarily access Qwen services. These patterns provide insight into how the platform is being used in real-world environments.
- 27.52% of all recorded Qwen website traffic originates from Iraq, making it the largest single national source of users accessing the platform across web and mobile environments.

- 19.08% of Qwen’s total web traffic is generated by users located in Brazil, indicating strong adoption across South America and Portuguese-speaking markets.
- 12.10% of Qwen platform traffic comes from Turkey, showing consistent usage across both desktop and mobile access points in that region.
- 10.60% of all measured Qwen traffic is attributed to users in Russia, reflecting substantial engagement from Eastern European and Eurasian markets.
Qwen Multimodal and Image Model Performance
Qwen includes specialized multimodal systems designed to generate, edit, and understand images alongside text. These models are evaluated using public image generation, editing, and text rendering benchmarks. The benchmark results measure how well Qwen models handle complex layouts, multilingual text, and visual fidelity. Performance on these tasks indicates how effectively Qwen can support design, content creation, and document processing workflows.
- Qwen-Image achieved a score of 88.32 on the GenEval benchmark, measuring general image generation quality against competing foundation models.
- Qwen-Image recorded 83.84 on the GSO benchmark, which evaluates object consistency and structural accuracy in edited images.
- Qwen-Image reached 58.30 on the LongText-Bench English text rendering benchmark, reflecting its ability to render long, structured text inside images.
- Qwen-Image achieved 0.946 on the OneIG-Bench English text rendering benchmark, measuring precision in complex typographic layouts.
- Qwen-Image scored 0.963 on the Chinese text rendering benchmark, indicating strong performance in logographic language image generation.
Qwen Enterprise Integration and Workplace Usage
Qwen is embedded inside enterprise productivity platforms and corporate AI workflows through Alibaba Cloud and workplace software integrations. These deployments support document processing, customer service, analytics, and internal automation. Enterprise usage metrics provide insight into how Qwen is being used beyond public applications. The scale of these integrations shows how deeply Qwen has penetrated organizational infrastructure.
- More than 2.2M corporate users actively use Qwen through its DingTalk workplace integration for daily productivity and collaboration tasks.
- Over 90,000 enterprises have deployed Qwen models through Alibaba Cloud Model Studio to power internal and customer-facing applications.
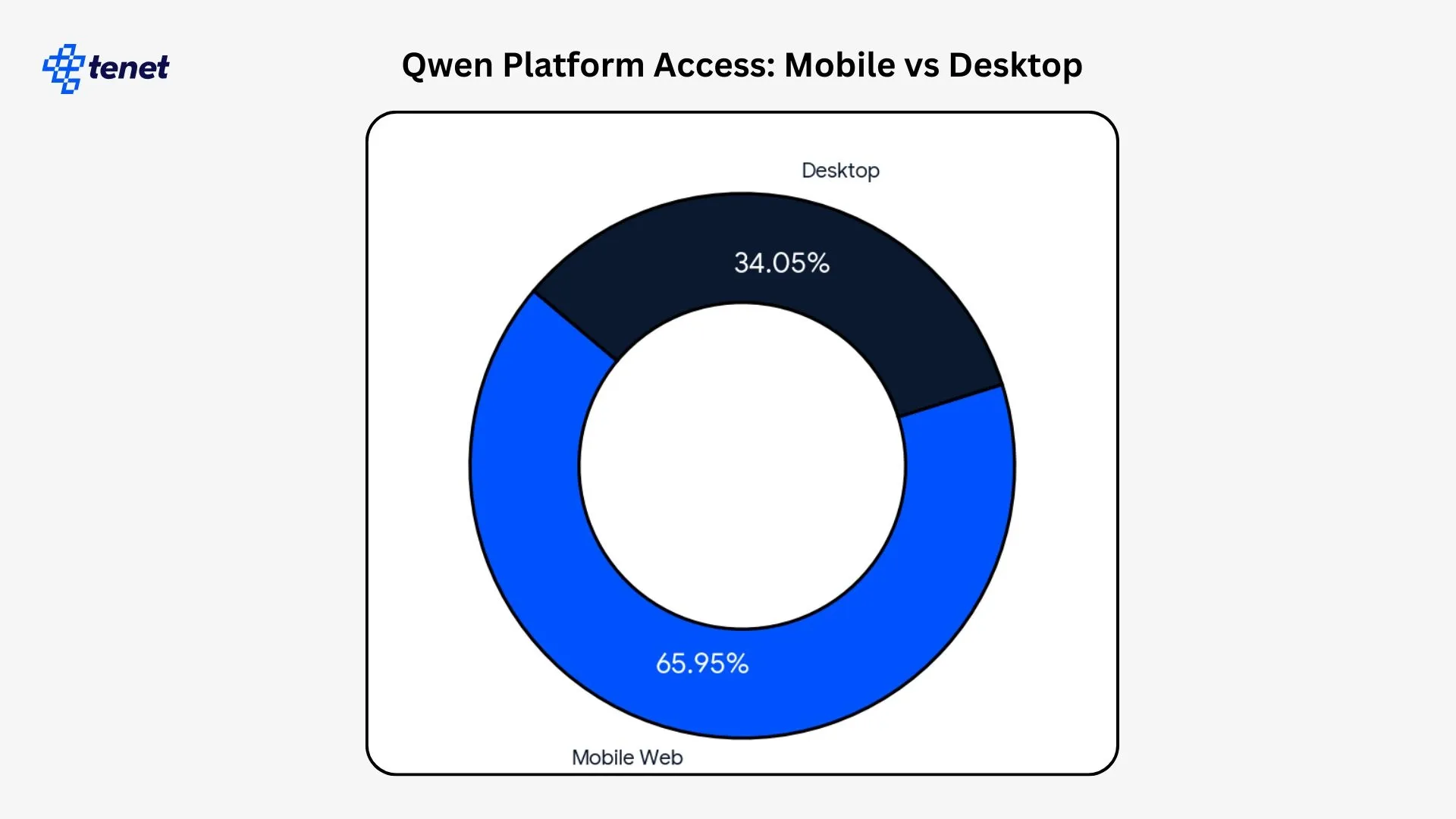
- 65.95% of Qwen users access the platform through mobile web devices, while 34.05% connect through desktop systems, demonstrating a strong mobile-first usage pattern.
- Qwen supports more than 100,000 free AI presentation templates that are used for enterprise slide generation and reporting.
- Qwen’s AI writing system is deployed across 1,000 universities and supports more than 10,000 legal and business contract templates.
Qwen Benchmark Performance and Capability Metrics
Qwen models are evaluated across standardized academic and competitive benchmarks that measure reasoning, knowledge coverage, and code generation. These benchmarks provide comparable performance signals against other large language models used in research and enterprise environments.
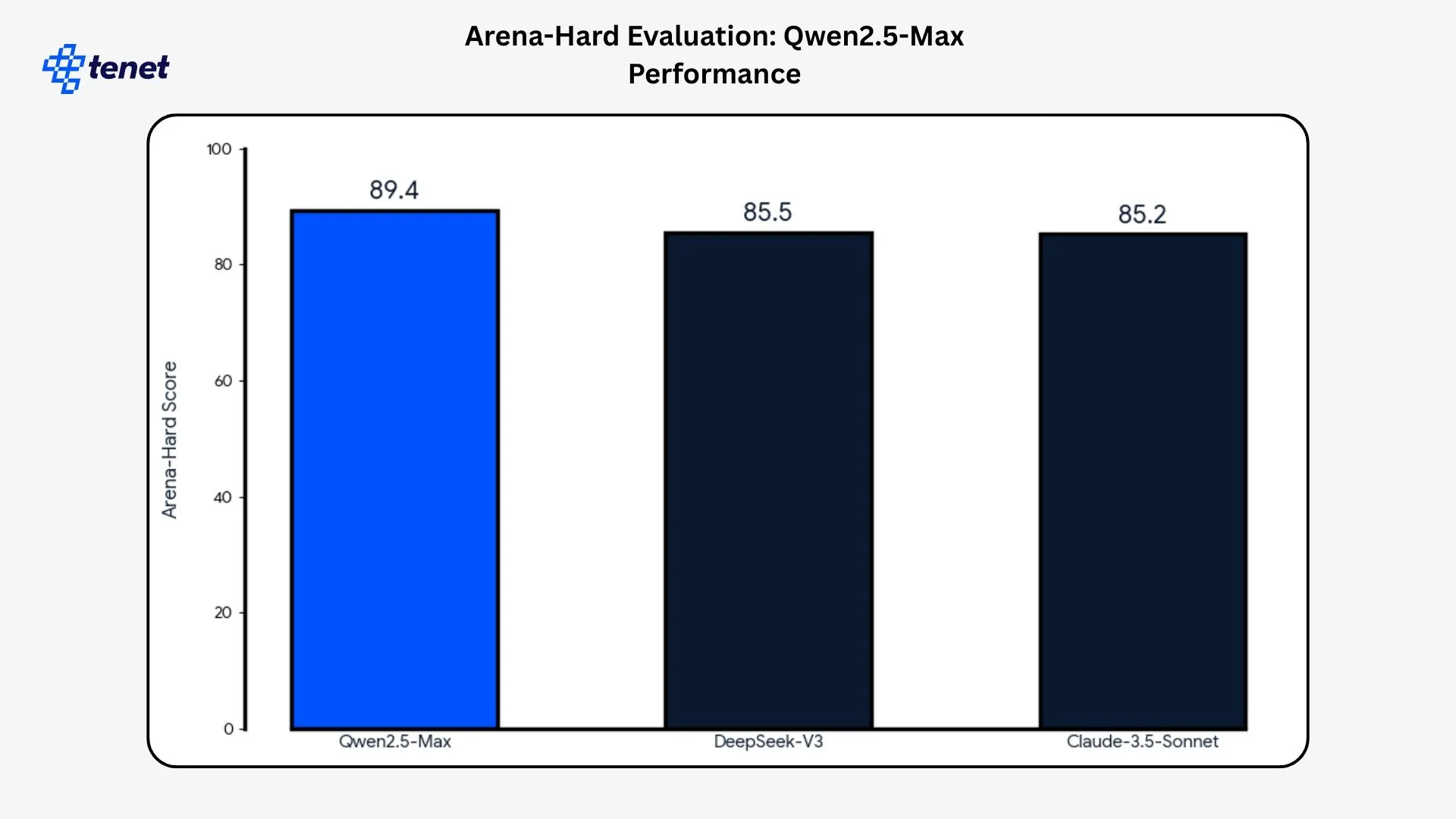
- On the Arena-Hard evaluation, Qwen2.5-Max comes out on top with an 89.4 score, creating a clear separation from DeepSeek-V3 (85.5) and Claude-3.5-Sonnet (85.2). That lead indicates stronger alignment with human judgment rather than marginal noise.
- Qwen2.5-Max recorded 76.1 on the MMLU-Pro benchmark, which measures broad academic and professional knowledge across multiple subject domains.
- Qwen2.5-Max achieved a score of 38.7 on LiveCodeBench, indicating its competitive performance on real-time programming and code generation challenges.
- Qwen2.5-Max reached 62.2 on LiveBench, a benchmark designed to evaluate general reasoning, tool use, and real-world problem solving.
- Qwen’s math problem-solving system achieved 84% accuracy on structured mathematics tasks used for automated grading and educational applications.
Final Words
Qwen has moved past early adoption. It now runs inside real products, business systems, and daily workflows at global scale.
The next phase will focus on deeper enterprise integration, stronger multimodal capabilities, and tighter alignment with real world tasks like coding, analytics, design, and automation.
We can expect faster models, lower deployment costs, and more domain specific versions tuned for regulated industries, regional languages, and on device use. As open source adoption continues to grow, Qwen will likely play a larger role in how organizations build, deploy, and scale AI systems across teams and markets.
FAQs
How widely is Qwen used across consumer and enterprise platforms?
Qwen has recorded more than 700M cumulative model downloads and reached over 30M monthly active users across its mobile, web, and desktop platforms, showing that the system is being used at both consumer scale and inside enterprise production environments.
How strong is Qwen’s performance on professional and academic benchmarks?
Qwen2.5 achieved an overall accuracy of 88.9% across 1,200 questions on the Chinese National Nursing Licensing Examination, while the flagship Qwen3-235B-A22B model scored 85.7 on AIME 2024 and 81.5 on AIME 2025, demonstrating high performance in both medical and mathematical evaluation settings.
What makes Qwen different from other large language model families?
The Qwen model family includes dense and Mixture-of-Experts systems ranging from 0.6B to 235B parameters and supports up to 119 languages and dialects, allowing the same ecosystem to serve lightweight applications as well as large-scale enterprise and research workloads.
How capable is Qwen in coding and real-world problem-solving?
The Qwen3-235B-A22B model achieved a CodeForces score of 2,056 and a LiveCodeBench score of 38.7, indicating strong competitive programming performance and effective handling of real-time software development tasks.
How does Qwen perform in multimodal and image-based AI tasks?
Qwen-Image achieved a score of 88.32 on the GenEval benchmark, 0.946 on OneIG-Bench English text rendering, and 0.963 on Chinese text rendering tasks, reflecting high-quality image generation, editing, and multilingual visual text synthesis.
👉 Explore other statistical roundups published at Tenet:
- Nano Banana Statistics
- 50+ Personal Branding Statistics Backed by Research
- 40+ AI in Application Development Statistics
- Website Speed and Page Load Time Statistics
Data Sources
- https://huggingface.co/Qwen/Qwen-3
- https://arxiv.org/abs/2505.09388
- https://github.com/QwenLM/Qwen3
- https://huggingface.co/Qwen/Qwen-Image
- https://arxiv.org/abs/2508.02324
- https://github.com/QwenLM/Qwen-Image
- https://arxiv.org/abs/2309.16609
- https://doi.org/10.38124/ijisrt/25sep899
- https://medinform.jmir.org/2025/1/e63731
Expertise Delivered Straight to Your Inbox
Expertise Delivered Straight to Your Inbox























Got an idea on your mind?
We’d love to hear about your brand, your visions, current challenges, even if you’re not sure what your next step is.
Let’s talk



